❗️이 포스팅은 인프런의 [스프링 입문 - 코드로 배우는 스프링 부트, 웹 MVC, DB접근 기술] 강의를 정리한 내용입니다.❗️
[무료] 스프링 입문 - 코드로 배우는 스프링 부트, 웹 MVC, DB 접근 기술 - 인프런 | 강의
스프링 입문자가 예제를 만들어가면서 스프링 웹 애플리케이션 개발 전반을 빠르게 학습할 수 있습니다., 스프링 학습 첫 길잡이! 개발 공부의 길을 잃지 않도록 도와드립니다. 📣 확인해주세
www.inflearn.com
[스프링 입문기 3] Welcome 페이지 만들기
Welcome Page 만들기
- 사용자가 도메인을 타고 들어왔을 때 보이는 첫 화면이 된다.
- 경로 : src/main/resources/static/index.html
- index.html 파일 추가해주기
<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html" charset="UTF-8">
<title>Hello</title>
</head>
<body>
hello
<a href="/hello">hello</a>
</body>
</html>- 서버를 다시 실행해주면 다음과 같은 화면을 확인할 수 있다.
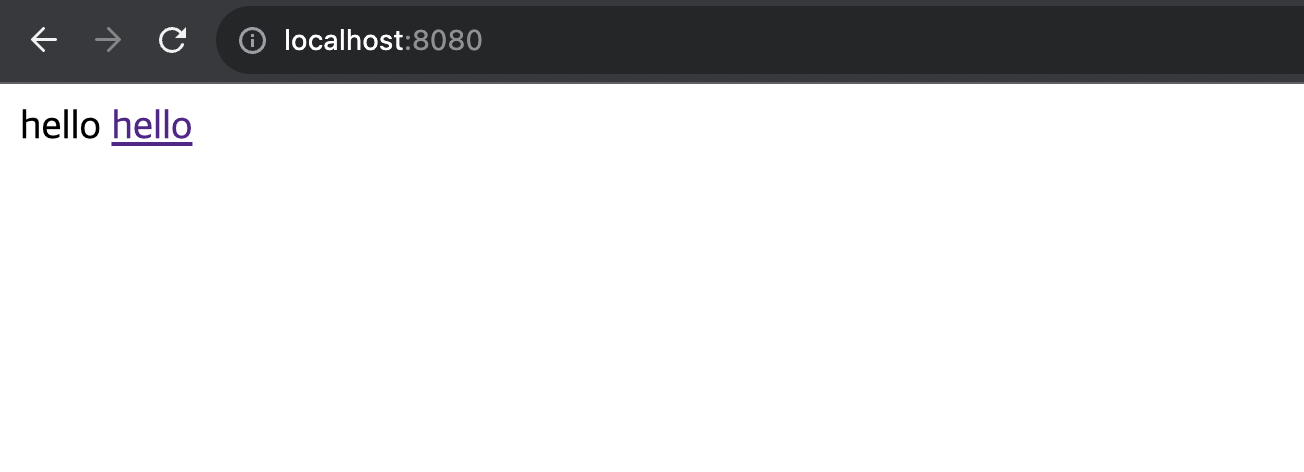
- 이와 같이 static 폴더 안에 index.html 파일을 추가하면, 스프링 부트에서 자동적으로 이 index.html 파일을 홈화면으로 기능한다.
thymeleaf 템플릿 엔진
- index.html은 정적(static) 페이지이기 때문에, 내가 원하는 대로 페이지를 수정하기 위해서는 템플릿 엔진이 필요하다.
- Spring Boot 템플릿 엔진 종류
- FreeMarker
- Groovy
- Thymeleaf (가장 많이 사용되는 템플릿 엔진 중 하나)
- Mustache
Controller 만들기
- Controller는 web application의 첫 진입점이 된다.
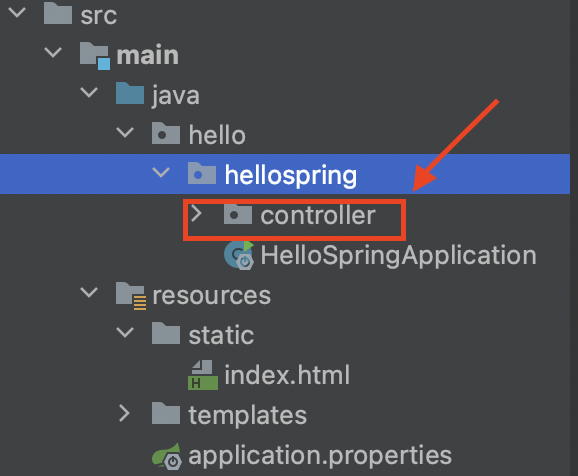
- hellospring 폴더 내부에 controller 패키지를 하나 만들어준다.

- controller 패키지 안에 HelloController 클래스를 생성해준다.
- HelloController 클래스 내에 다음 코드를 작성한다.
package hello.hellospring.controller;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class HelloController {
@GetMapping("hello") // 웹 어플리케이션이 /hello로 들어오면 이 함수를 실행
public String hello(Model model ) {
model.addAttribute("data", "hello");
return ("hello"); // template 중에서 hello.html을 실행하라는 의미
}
}템플릿 추가하기
- src/main/resources/templates 폴더 안에 hello.html 파일을 추가한다.

- hello.html 파일에 다음 코드를 작성해준다.
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaft.org">
<head>
<meta http-equiv="Content-Type" content="text/html" charset="UTF-8">
<title>Hello</title>
</head>
<body>
<p th:text="'안녕하세요. '+ ${data}">안녕하세요 손님.</p>
</body>
</html>- localhost:8080/hello로 들어가보면 다음과 같이 "data" 속성에 저장했던 "hello"값으로 바뀌어 출력되는 것을 볼 수 있다.

작동 원리

- 웹 브라우저에서 /hello 로 접근 하면 스프링 부트에 내장되어 있는 톰켓 서버에서 이를 받아 spring 컨테이너에 던져줌.
- 컨트롤러 내부에 @GetMapping("hello")를 찾아서 해당 메서드를 실행
- model에는 key:value 값을 저장 (여기서는 data:hello!!)
- return "hello"를 하면 templates/hello.html를 찾아감. (thymeleaf 템플릿 엔진 처리)
- 컨트롤러에서 리턴 값으로 문자를 반환하면 viewResolver가 화면을 찾아서 처리한다.
- 스프링 부트 템플릿엔진 기본 viewName 매핑
- 'resources/templates/' + {viewName} + '.html'
반응형
SMALL
'Computer Science > Spring' 카테고리의 다른 글
| [스프링 입문기 5] 스프링 웹개발 기초 (0) | 2023.08.03 |
|---|---|
| [스프링 입문기 4] 빌드 및 실행하기 (0) | 2023.08.03 |
| [스프링 입문기 2] 라이브러리 살펴보기 (0) | 2023.08.01 |
| [스프링 입문기 1] 프로젝트 환경설정/첫 프로젝트 실행해보기 (0) | 2023.08.01 |