아래 사이트(Machine Learning For Kids)에서 정말 간단하게 챗봇을 위한 인공지능 모델을 구축하고 사용해 볼 수 있다. 앱 인벤터를 이용하면 이 챗봇을 간단하게 앱으로도 구현해 볼 수 있다. 플랫폼과 파이썬을 사용하여 간단한 인공지능 챗봇을 구축해보고자 한다.
Machine Learning for Kids
An educational tool for teaching kids about machine learning, by letting them train a computer to recognise text, pictures, numbers, or sounds, and make things with it in Scratch.
machinelearningforkids.co.uk
챗봇(ChatBot)이란?
우선, 챗봇이 무엇인지부터 알아보자. 챗봇은 ChatterBot의 약자로서, 말 그대로 이야기를 주고받는 로봇을 의미한다.
챗봇은 크게 트랜잭션 챗봇과 대화형 챗봇으로 나눌 수 있다.
- 트랜잭션 챗봇 : 하나의 기능을 수행하거나 자동화하는 데 주력하는 단일 용도의 챗봇을 말한다. 예를 들어 레스토랑이나 택배 회사, 은행 등에서 간단한 질문에 답하거나 업무를 수행할 때 사용된다.
- 대화형 챗봇 : 보다 개인 맞춤화된 상호 작용에 사용되는 챗봇을 말한다. 트랜잭션 챗봇처럼 단일 용도로 사용되는 것이 아니라 사용자와 상호작용하며 마치 사람과 대화를 하듯 답변하도록 설계된다. 대표적으로 ChatGPT가 있을 것이다.
챗봇 구현하기
이제 실제 챗봇을 구현하기 위한 모델을 위 플랫폼을 사용하여 구축해보자. 여기서는 호텔 안내 서비스 챗봇을 만들어 볼 예정이다.
1. 프로젝트 만들기
가장 먼저 머신러닝 프로젝트를 만들어야 한다. 우측에 있는 프로젝트 추가 버튼을 클릭한다.

그다음, 프로젝트의 세부사항을 입력한다. 여기서는 호텔 안내 챗봇을 만들어볼 것이기 때문에 프로젝트 이름은 "Hotel", 인식은 "텍스트", 언어는 "Korean"으로 선택하였다.

2. 훈련
프로젝트를 생성하면 다음과 같은 페이지가 나온다. 모델을 훈련시키기 위하여 가장 좌측에 있는 [훈련] 버튼을 클릭하자.

[훈련] 버튼을 클릭하면 다음과 같은 페이지가 나온다. 여기서 우측에 있는 [새로운 레이블 추가] 버튼을 누르고 자신의 챗봇에 맞는 질문 레이블을 추가하면 된다. 여기서는 호텔 안내 서비스이기 때문에 총 6개의 레이블(reservation, facility, location, service, price, checkinout)을 추가하였다.

그다음, 각 질문 레이블에 맞는 데이터를 추가한다. 데이터는 고객이 질문할 만한 질문 데이터들을 입력해 주면 된다. 한 레이블당 약 7개 정도의 데이터를 추가하였다. 데이터는 당연히 많을수록 좋다.

3. 학습 & 평가
이제 좌측 상단에 있는 [프로젝트로 돌아가기] 버튼을 누른 후, 학습&평가 버튼을 클릭하면 다음과 같은 화면이 나온다. 하단에 있는 [새로운 머신러닝 모델을 훈련시켜 보세요] 버튼을 클릭하자.
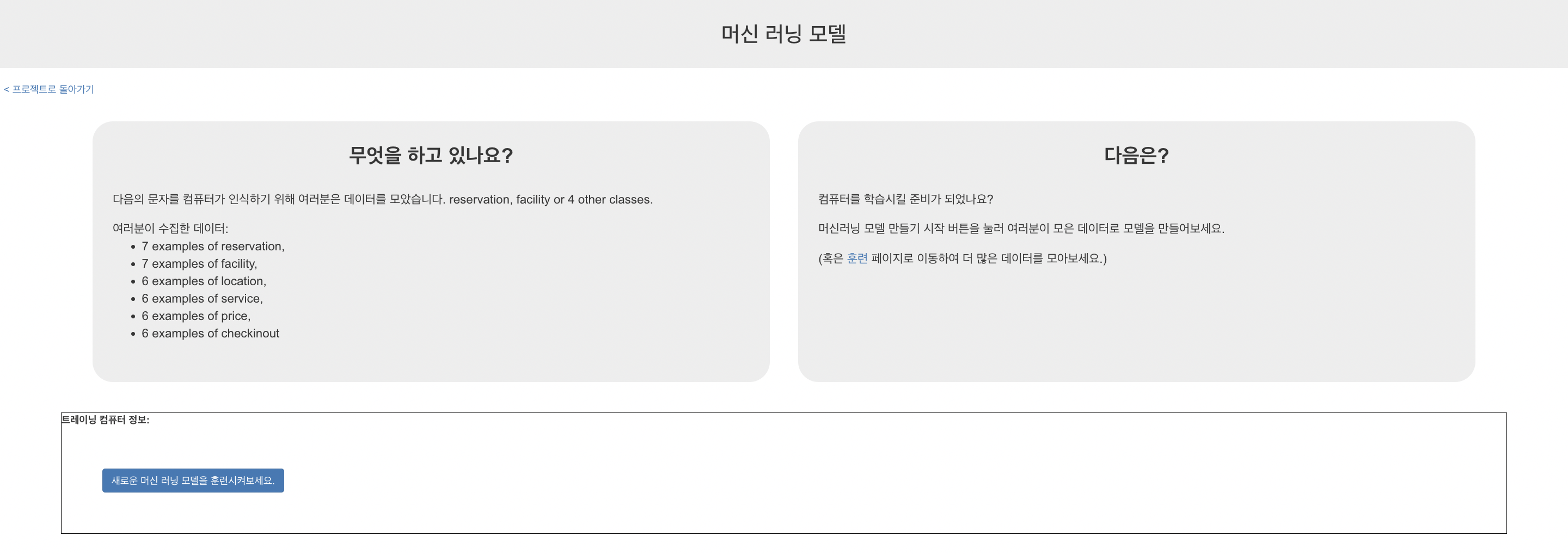
잘 학습이 완료되면 다음과 같은 페이지가 나온다. 모델이 잘 학습되었는지 간단하게 문자를 넣어 테스트도 해볼 수 있다.

간단하게 테스트를 진행해 본 결과는 다음과 같다. 인식된 레이블의 이름과 confidence 값이 함께 출력되는 것을 확인할 수 있다.

4. 만들기
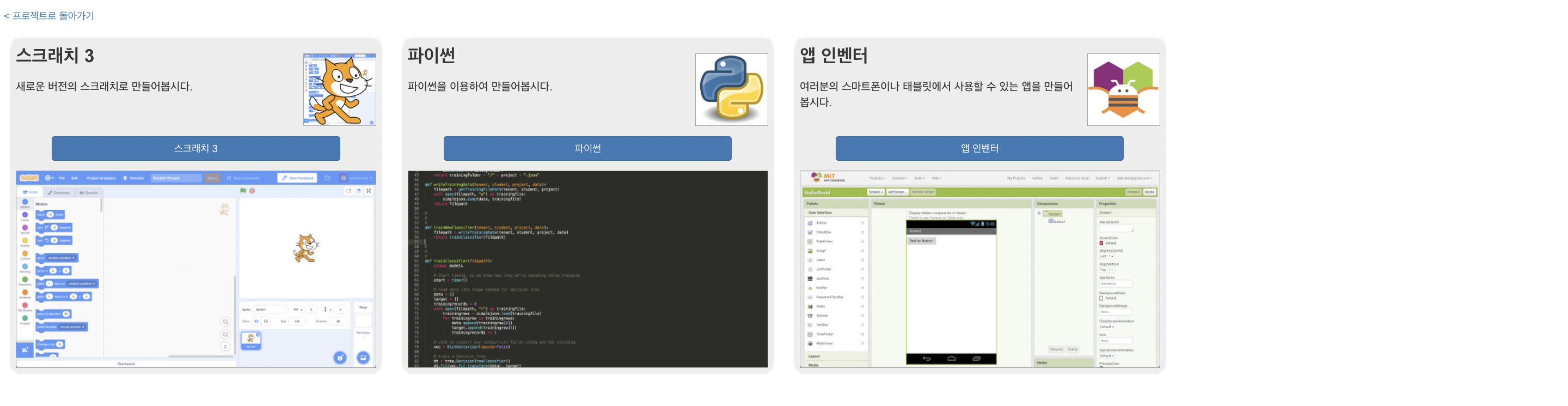
이제 이 구축된 모델을 이용하여 챗봇을 만들어볼 것이다. 프로젝트로 돌아가서 만들기를 누르면 다음과 같은 화면이 나온다. 보다시피 스크래치나 파이썬, 앱 인벤터로 간단하게 챗봇을 만들 수 있다. 여기서는 파이썬을 이용해 볼 것이다.
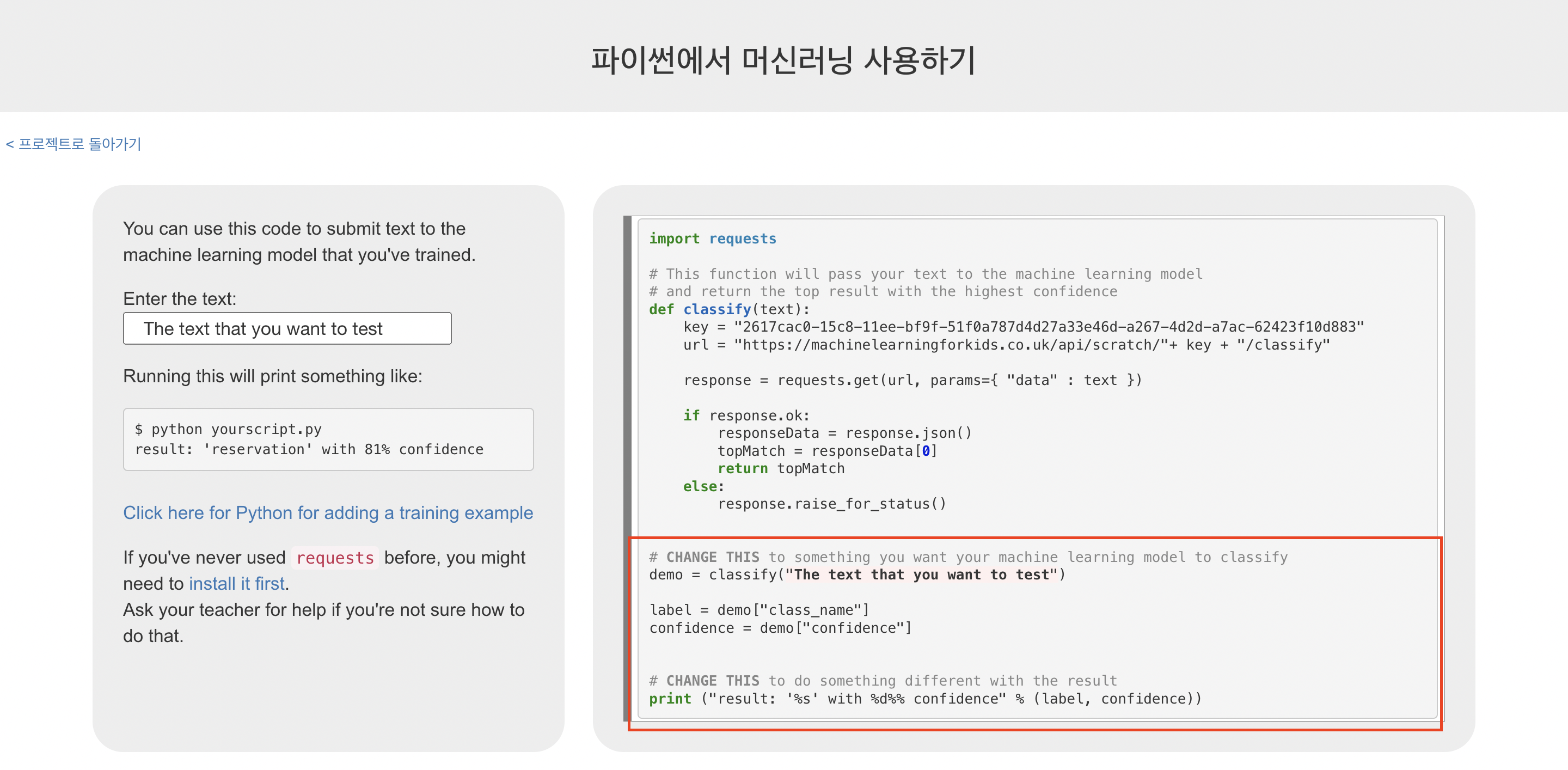
[파이썬] 버튼을 클릭하면 다음과 같은 화면이 나온다. 여러 방법이 소개되어 있는데, 코랩에 연결하여 사용하기 위해 우측에 있는 [내 컴퓨터에서 실행하도록 코드를 복사하세요.] 버튼을 클릭한다.

그러면 다음과 같은 페이지가 나오고, 이 코드를 복사하여 그대로 코랩에 붙여 넣기 한다. 사진에서 빨간색 부분만 수정가능하다.
각 질문 레이블에 맞는 답변을 다음과 같이 구성하였다.
while True:
question = input("호텔에 대해서 궁금한 것을 저에게 물어보세요! 질문이 끝나시면 '나가기'를 입력해주세요.")
if (question == "나가기") :
break
answer = classify(question)
label = answer["class_name"]
confidence = answer["confidence"]
if confidence < 60 :
print("제가 질문을 잘 이해하지 못했어요. 다시 질문해주세요.")
elif (label == "reservation") :
print("호텔 예약과 관련된 정보는 저희 호텔 홈페이지에서 확인하실 수 있습니다.")
print("답변 정확도 :", confidence)
elif (label == "facility") :
print("저희 호텔에는 헬스장, 수영장, 식당 등이 있습니다. 자세한 사항은 저희 호텔 홈페이지를 참고해주세요.")
print("답변 정확도 :", confidence)
elif (label == "location") :
print("저희 호텔은 서울특별시 강남구에 위치해있습니다. 강남역 바로 앞에 위치해 있어 교통이 편리합니다.")
print("답변 정확도 :", confidence)
elif (label == "service") :
print("저희 호텔은 전 객실 와이파이가 가능하며, 룸서비스 및 어메니티 서비스를 이용하실 수 있습니다.")
print("답변 정확도 :", confidence)
elif (label == "price") :
print("호텔 객실 요금 정보는 저희 호텔 홈페이지에서 확인해주세요.")
print("답변 정확도 :", confidence)
elif (label == "checkinout") :
print("체크인 시간은 오후 3시이며, 체크아웃 시간은 오후 12시입니다.")
print("답변 정확도 :", confidence)5. 실행결과
실행 결과는 다음과 같다.
- 입력 : 호텔 예약을 하고 싶어요.
- 출력 : 호텔 예약과 관련된 정보는 저희 호텔 홈페이지에서 확인하실 수 있습니다. / 답변 정확도 : 82
- 입력 : 체크인은 언제부터 가능한가요.
- 출력 : 체크인 시간은 오후 3시이며, 체크아웃 시간은 오후 12시입니다. / 답변 정확도 : 98
- 입력 : 헬스장을 이용할 수 있나요.
- 출력 : 제가 질문을 잘 이해하지 못했어요. 다시 질문해주세요.
마치며..
Dialogflow로도 간단하게 챗봇을 구축할 수 있지만, 인공지능을 처음 배우는 학생들에게는 조금 난이도가 어려울 것 같아서 machine learning for kids 플랫폼을 사용하였다. 요즘 핫한 ChatGPT 정도의 챗봇을 만드는 것은 당연히 불가능하지만 난이도도 어렵지 않고 다양하게 활용이 가능해서 학생들이나 처음 인공지능을 공부하는 사람들에게는 한 번쯤 활용해 볼 만한 플랫폼인 것 같다.
'인공지능 > NLP' 카테고리의 다른 글
| 챗GPT와 제대로 대화하기 - 프롬프트 엔지니어링, "Act as~" Hack (16) | 2023.06.26 |
|---|