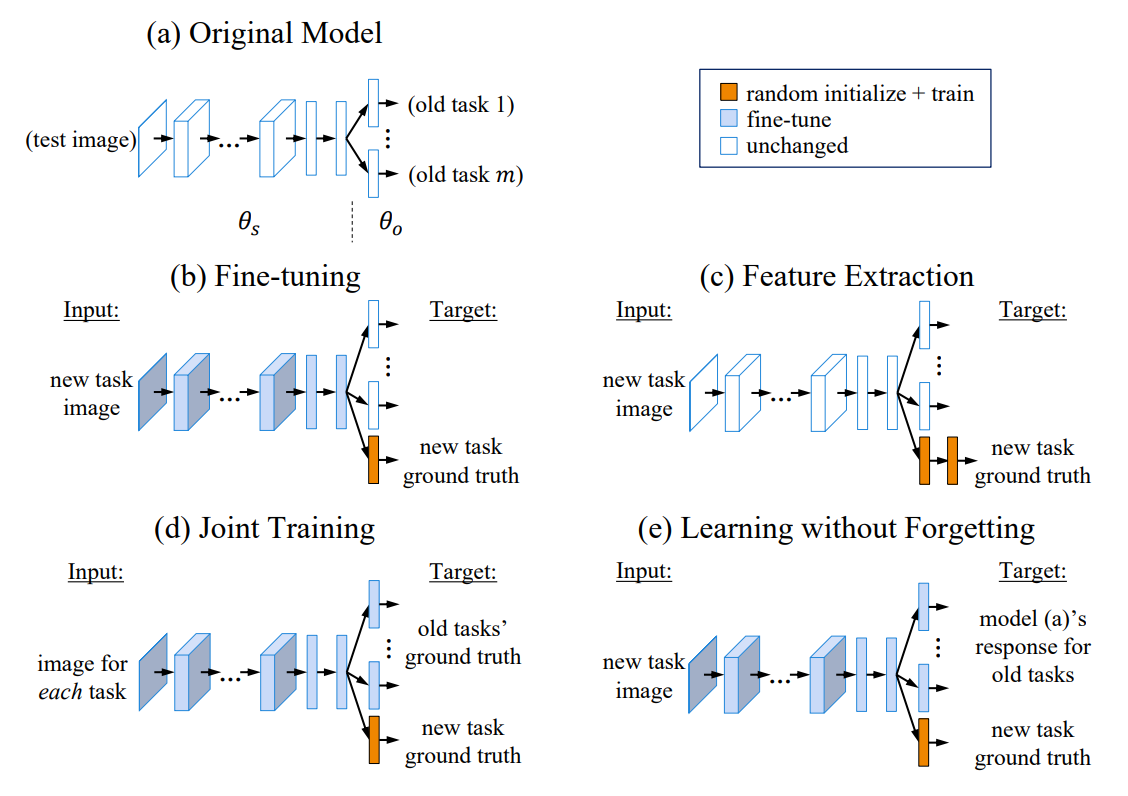
1. LeNet-5란?
LeNet-5은 1998년에 개발된 초기 CNN 구조로, 이후 딥러닝의 기반을 마련한 모델이라고 할 수 있다.

2. 각 Layer 살펴보기
(1) Input Layer (입력층)
LeNet-5의 입력은 32x32 크기의 흑백 이미지이다. Input 이미지는 0과 1 사이의 값으로 정규화된다.
(2) C1 Layer (Convolution)
LeNet-5는 두 개의 Convolution Layer을 가지고 있는데, 첫 번째 Convolution layer는 6개의 5x5 크기의 필터를 사용한다. 합성곱 연산 결과 6장의 28x28 feature map을 얻게 된다. 활성화 함수는 sigmoid 함수를 사용한다.
(3) S2 Layer (Subsampling)
Convolution layer 이후 평균 풀링을 진행한다. 2x2 window와 stride 2를 사용하여 feature map이 반으로 줄어든다. 즉, 결과적으로 6장의 14x14 feature map을 얻게 된다.
(4) C3 Layer (Convolution)
두번째 Convolution layer는 첫 번째 합성곱 레이어와 유사한 구조를 가지고 있지만, feature map의 깊이가 6에서 16으로 증가한다. 이 층에서도 활성화 함수는 sigmoid 함수를 사용한다.
(5) S4 Layer (Subsampling)
첫 번째 평균 풀링 layer와 마찬가지로 2x2 window와 stride 2를 사용하여 입력 이미지의 공간 해상도를 다시 줄입니다.
(6) C5 Layer (Convolution)
16장의 5 x 5 특성맵을 120개의 5 x 5 x 16 사이즈의 필터와 합성곱 연산을 진행한다. 결과적으로 120개의 1 x 1 feature map이 나온다.
(7) F6 (Fully Connected Layer)
이제 입력 이미지는 Fully Connected Layer로 전달된다. 이 layer는 86개의 뉴런으로 구성되어 있으며, 이전 layer의 모든 feature map과 연결된다. Fully Connected Layer는 입력에 대한 weight 합과 bias을 계산하고, sigmoid 활성화 함수를 사용한다.
(8) Output Layer (출력층)
LeNet-5의 출력층은 10개의 뉴런으로 구성되어 있다. 이 레이어는 입력 이미지가 0부터 9까지의 숫자를 나타내는 확률 분포로 매핑되도록 설계되었다. 출력 뉴런 중 가장 높은 값을 가진 뉴런이 모델의 예측 결과로 사용되는 것이다.
3. Tensorflow 코드 구현하기
(1) 필요 라이브러리 가져오기
import numpy as np
import tensorflow as tf
import tensorflow.keras.datasets as ds
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D,MaxPooling2D,Flatten,Dropout,Dense
from tensorflow.keras.optimizers import Adam(2) 데이터셋 전처리
(x_train,y_train),(x_test,y_test)=ds.mnist.load_data()
x_train=x_train.reshape(60000,28,28,1) # 60000개의 데이터 -> 28x28x1 (grayscale)
x_test=x_test.reshape(10000,28,28,1) # 10000개의 데이터 -> 28x28x1 (grayscale)
x_train=x_train.astype(np.float32)/255.0 # 0~255의 픽셀 값 -> 0~1 사이의 값으로 정규화
x_test=x_test.astype(np.float32)/255.0
y_train=tf.keras.utils.to_categorical(y_train,10) # 0~9 값을 원핫 코드로 변환
y_test=tf.keras.utils.to_categorical(y_test,10)(3) 층 쌓기
cnn=Sequential()
# C1 : 6개 5x5 filter, zero padding -> output_shape = (28, 28, 6)
cnn.add(Conv2D(6,(5,5),padding='same',activation='relu',input_shape=(28,28,1)))
# S2 : 2x2 filter, stride = 2 -> output_shape = (14, 14, 6)
cnn.add(MaxPooling2D(pool_size=(2,2),strides=2))
# C3 : 16개 5x5 filter, padding 안함 -> output_shape = (10, 10, 16)
cnn.add(Conv2D(16,(5,5),padding='valid',activation='relu'))
# S4 : 2x2 filter, stride = 2 -> output_shape = (5, 5, 16)
cnn.add(MaxPooling2D(pool_size=(2,2),strides=2))
# C5 : 120개 5x5 filter, padding 안함 -> output_shape = (1, 1, 120)
cnn.add(Conv2D(120,(5,5),padding='valid',activation='relu'))
# 120
cnn.add(Flatten())
# 120 -> 84
cnn.add(Dense(units=84,activation='relu'))
# 84 -> 10
cnn.add(Dense(units=10,activation='softmax'))(4) 학습, 정확도 계산
cnn.compile(loss='categorical_crossentropy',optimizer=Adam(learning_rate=0.001),metrics=['accuracy'])
cnn.fit(x_train,y_train,batch_size=128,epochs=50,validation_data=(x_test,y_test),verbose=2)
res=cnn.evaluate(x_test,y_test,verbose=0)
print('accuracy=',res[1]*100)
'인공지능 > 컴퓨터비전' 카테고리의 다른 글
| [YOLOv8] 커스텀 데이터셋으로 Object Detection해보기 (0) | 2023.11.09 |
|---|---|
| [OpenCV] Python으로 간단하게 Face Detection 구현하기 (1) | 2023.06.24 |
| [OpenCV] Python OpenCV 라이브러리 설치하기 (0) | 2023.06.24 |
| [OpenCV] Data Augmentation 구현하기 (0) | 2023.06.24 |